
One of the advantages of being a “data scientist” is that everyone assumes you know what you’re talking about. While that has its privileges, more important to the craft is the ability to leverage statistical programming packages, such as R and Python, and apply them to almost any question that can be answered through data.

Click here for more PFF tools:
Rankings & Projections | WR/CB Matchup Chart | NFL & NCAA Betting Dashboards | NFL Player Props tool | NFL & NCAA Power Rankings
I publish analyses on the single-game DraftKings showdown slates that use the combination of current projections, historical game results and similarity algorithms to simulate an upcoming game by looking back at the most similar historical matchups. In this analysis, I’m taking the same outline and applying it instead to the DFS main slate by projecting the likelihood each individual quarterback, running back, wide receiver, tight end and D/ST option will be the highest scorer of the slate. In doing this, we can find the unlikely tournament plays who may not have been on your radar.
METHODOLOGY
For each game on the DFS Sunday main slate, I looked through thousands of NFL matchups from 2014-2021 and found the closest analogies according to the following parameters: Betting spread, over/under and average fantasy points scoring for the top-ranked positional players of both rosters (QB1, RB1, WR1, TE1).
Once I find the 75 most similar matchups for each upcoming game, I then simulate the main slate 10,000 times by randomly choosing one of the 75 matchups for each game. Then, I find the highest-scoring quarterback, running back, wide receiver, tight end and D/ST on the entire slate.
The last step is totaling the number of times a particular team shows up as the top option for the slate at each position and dividing by the total simulations. That number is what I call “highest-scoring %” in the team-labeled bar charts below. Below the charts, I join the highest-projected player on that team for the position, then list their projected fantasy points and salaries for DraftKings and FanDuel.
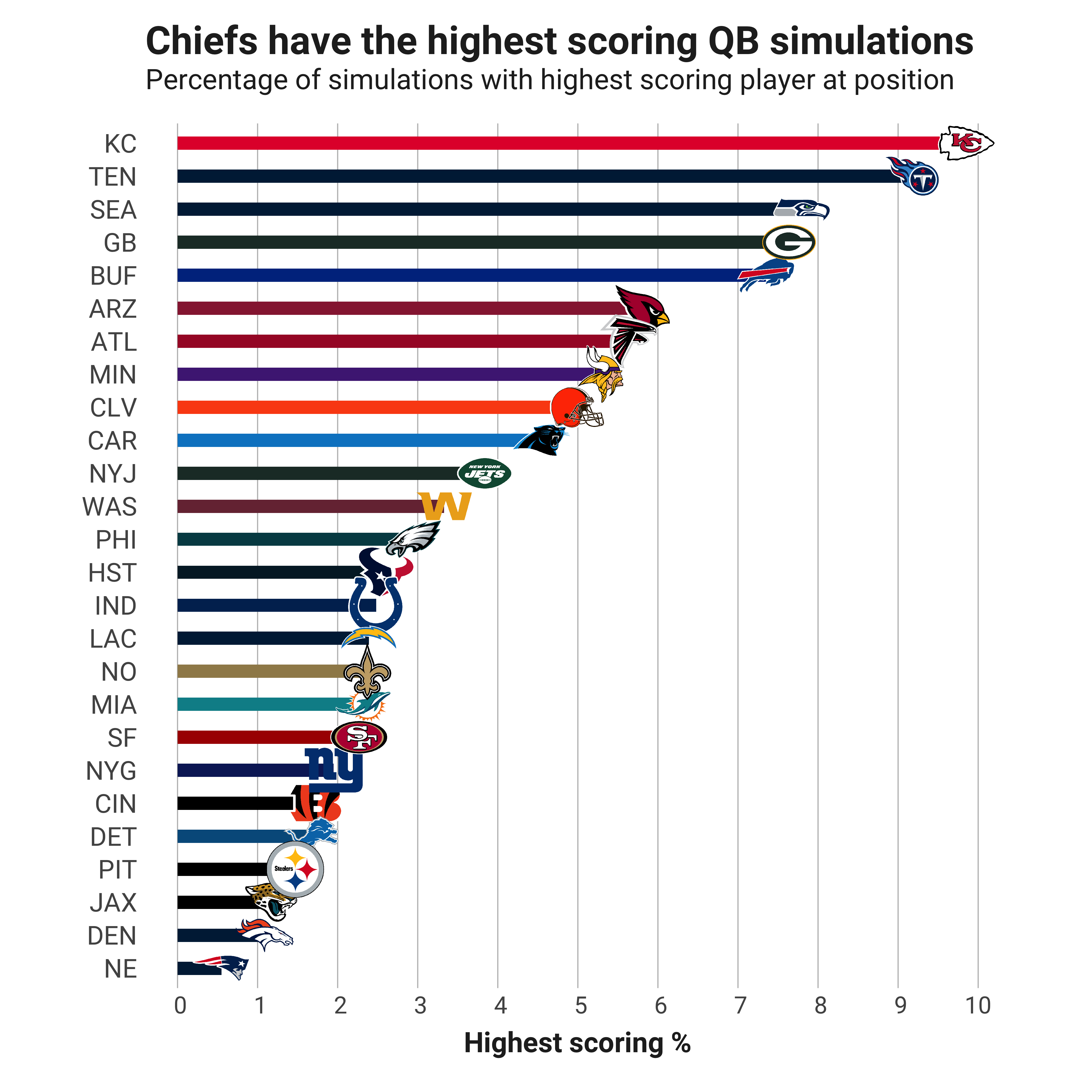
QUARTERBACKS
| Pos | Highest % | Player | Team | DK Fpts | DK Salary | FD Fpts | FD Salary |
| QB | 9.86 | Patrick Mahomes | KC | 26.3 | 8,100 | 24.5 | 8,800 |
| QB | 9.16 | Ryan Tannehill | TEN | 22.2 | 6,500 | 20.7 | 7,700 |
| QB | 7.80 | Russell Wilson | SEA | 22.9 | 7,000 | 21.5 | 7,800 |
| QB | 7.64 | Aaron Rodgers | GB | 22.4 | 6,800 | 20.9 | 8,000 |
| QB | 7.35 | Josh Allen | BUF | 23.9 | 7,400 | 22.3 | 8,100 |
| QB | 5.80 | Kyler Murray | ARZ | 21.6 | 7,600 | 20.4 | 8,400 |
| QB | 5.64 | Matt Ryan | ATL | 21.8 | 6,000 | 20.2 | 7,300 |
| QB | 5.28 | Kirk Cousins | MIN | 17.1 | 6,300 | 16.0 | 7,200 |
| QB | 5.00 | Baker Mayfield | CLV | 19.2 | 5,900 | 17.9 | 7,100 |
| QB | 4.55 | Sam Darnold | CAR | 18.8 | 5,000 | 17.4 | 6,500 |
| QB | 3.84 | Zach Wilson | NYJ | 17.3 | 5,000 | 16.2 | 6,500 |
| QB | 3.33 | Ryan Fitzpatrick | WAS | 19.4 | 5,500 | 18.0 | 6,600 |
| QB | 2.95 | Jalen Hurts | PHI | 19.4 | 6,400 | 18.2 | 7,600 |
| QB | 2.60 | Tyrod Taylor | HST | 19.7 | 5,300 | 18.3 | 6,800 |
| QB | 2.48 | Carson Wentz | IND | 16.3 | 5,600 | 15.3 | 6,500 |
| QB | 2.39 | Justin Herbert | LAC | 19.3 | 6,700 | 18.0 | 7,600 |
| QB | 2.37 | Jameis Winston | NO | 16.8 | 5,200 | 15.7 | 6,700 |
| QB | 2.32 | Tua Tagovailoa | MIA | 19.1 | 5,400 | 17.9 | 6,600 |
| QB | 2.27 | Jimmy Garoppolo | SF | 16.8 | 5,500 | 15.8 | 6,900 |
| QB | 1.95 | Daniel Jones | NYG | 19.2 | 5,300 | 17.8 | 6,700 |
| QB | 1.72 | Joe Burrow | CIN | 21.1 | 5,700 | 19.5 | 7,200 |
| QB | 1.67 | Jared Goff | DET | 18.9 | 5,100 | 17.2 | 6,500 |
| QB | 1.47 | Ben Roethlisberger | PIT | 15.7 | 6,100 | 14.6 | 7,100 |
| QB | 1.17 | Trevor Lawrence | JAX | 20.4 | 6,200 | 19.1 | 6,800 |
| QB | 1.09 | Teddy Bridgewater | DEN | 17.2 | 4,800 | 16.2 | 6,600 |
| QB | 0.55 | Mac Jones | NE | 17.6 | 4,400 | 16.5 | 6,200 |
