The Cleveland Browns last week announced a contract extension with stud runner Nick Chubb for three years at a little over $36 million. Some of the normal discussion of running back value ensued, but what’s lacking is a means of isolating the exact contribution Chubb brings as a top-notch running back who doesn’t contribute much in the passing game.
The NFL has become a passing league, and the total contract value of running backs has fallen as a percentage of cap from over 5.5% in 2013 to 4.0% in 2020. The league has clearly devalued the position, but has it done so enough?
In this analysis, I’m going to apply the PFF Plus-Minus methodology in the running game that I used to calculate the passing-game value of wide receivers, offensive tackles, edge rushers and cornerbacks into points. The foundational metric of the analysis is expected points added (EPA), which translates down, distance, field position and other contextual information for each play into an expected scoring value, which can then be compared as the game progresses to value the results of a play by the change in the offense’s expected points.

I'm not simply giving the EPA for different rushers on the plays where they carry the ball and assuming that it encapsulates value. Instead, I’m looking at how team performance shifts when each running back is given the ball and therefore stripping out team-level effects as best we can. This isolates the contribution of the running back.
Another key element of the analysis is clustering, or grouping, running backs based on their performance metrics and PFF grades, and using a broader selection of players to minimize the noise in an individual situation. Growing the sample is the means for reducing the noise in the situation for a single player. While we can’t grow one player’s sample, we can find that player’s closest counterparts and add their numbers to the sample. If one player like Nick Chubb provides a few hundred rushing plays on and off the field, finding 10 Chubb-like players will provide a few thousand. The higher you can reasonably build the sample, the more you can minimize noise and boost signal.
In this analysis, I'll walk through how to build similar groups of running backs by statistical similarity and then use the larger sample of the group to calculate more meaningful estimates for the value of its constituents. This lays the foundation to replicate the process further, producing estimates for the rushing value of each running back.
PLAYER CLUSTERING
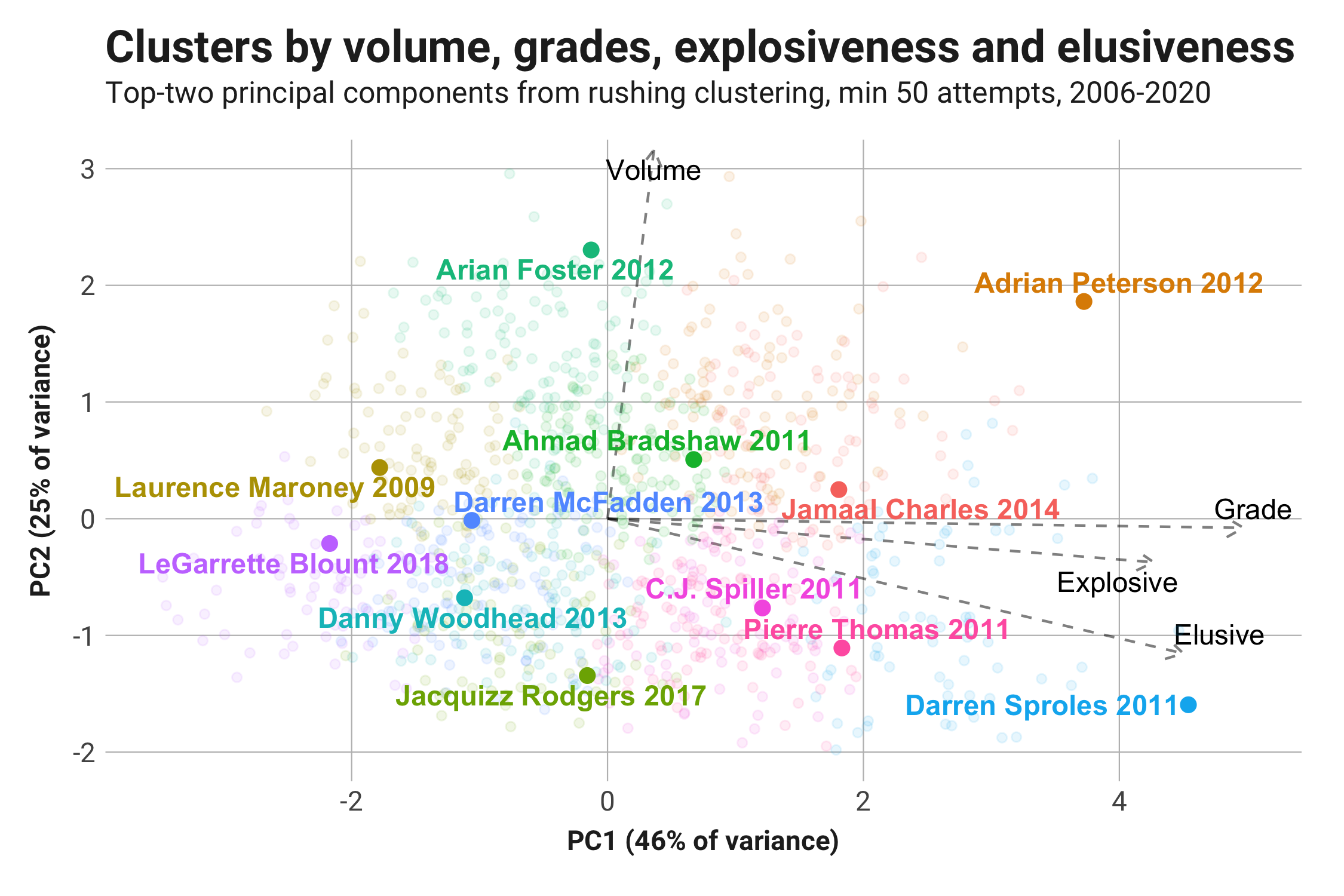
For this analysis, I’m using every season since 2006, and I'm only looking at running backs who had at least 50 carries throughout the single seasons over that span.
For each running back season, I calculated a number of efficiency and volume statistics and settled upon four for isolating the performance and capturing the type of the running back: rushing attempts per game (volume), PFF run grades (grade), avoided tackles per attempt (elusive) and percentage of runs gaining 15 or more yards (explosive). I translated these four features into principal components to minimize multicollinearity and make for easier visualization. The technique I used to form groups of similar running back seasons is called k-means clustering. With this clustering technique, you choose the number of clusters, or groups, to form.
Here, I’ll walk through an example of the clustering process. In this example, I chose to divide the roughly 1,000 runner seasons into 12 clusters.