
A few weeks ago, I released the methodology and top-12 all-time list for PFF Plus/Minus, a new way to value wide receivers, and I followed that up by applying the same methodology to cornerbacks last week. PFF Plus/Minus is built on historical on- and off- the field splits for players who are grouped by type in order to build larger, less-noisy samples of data that boost the usefulness of the information gathered. The full methodology is included in the first link above, and it's worth your review to get the most out of this analysis.
The problem with plus/minus data and on/off splits is that it’s difficult to pinpoint the effect of one player on the field, especially with small samples. The solution for reducing the noise in a single plus/minus split is growing the sample. While we can’t grow one player’s sample, we can find that player’s closest counterparts and add their numbers to the sample. If one player provides a few hundred snaps on and off the field a season, finding 10 similar players will provide a few thousand. The higher you can reasonably build the sample, the more you can minimize noise and boost signal.
In this analysis, I walk through how to build similar groups of edge defenders by statistical similarity and then use the larger sample of the group to calculate more meaningful estimates for the value of its constituents. This lays the foundation to further replicate the process, producing estimates for the value of each edge defender.
Player Clustering
For this analysis, I'm using every season since 2006, and I'm only looking at edge defenders who played at least 200 pass-rush snaps throughout the single seasons over that span.
For each edge season, I calculated a number of efficiency and volume statistics and settled upon six primary features to better differentiate edge types: pass-rush snaps per game, sacks per rush, quarterback hits per snap, quarterback hurries per snap, quarterback pressure per snap and PFF pass-rush grade per snap. I translated these six features, and many other minor features, into principal components to minimize multicollinearity and make for easier visualization. The technique I used to form groups of similar edge seasons is called k-means clustering. With this clustering technique, you choose the number of clusters, or groups, to form.
Here, I’ll walk through an example of the clustering process. In this example, I chose to divide the 1,200-plus edge seasons into 12 clusters.
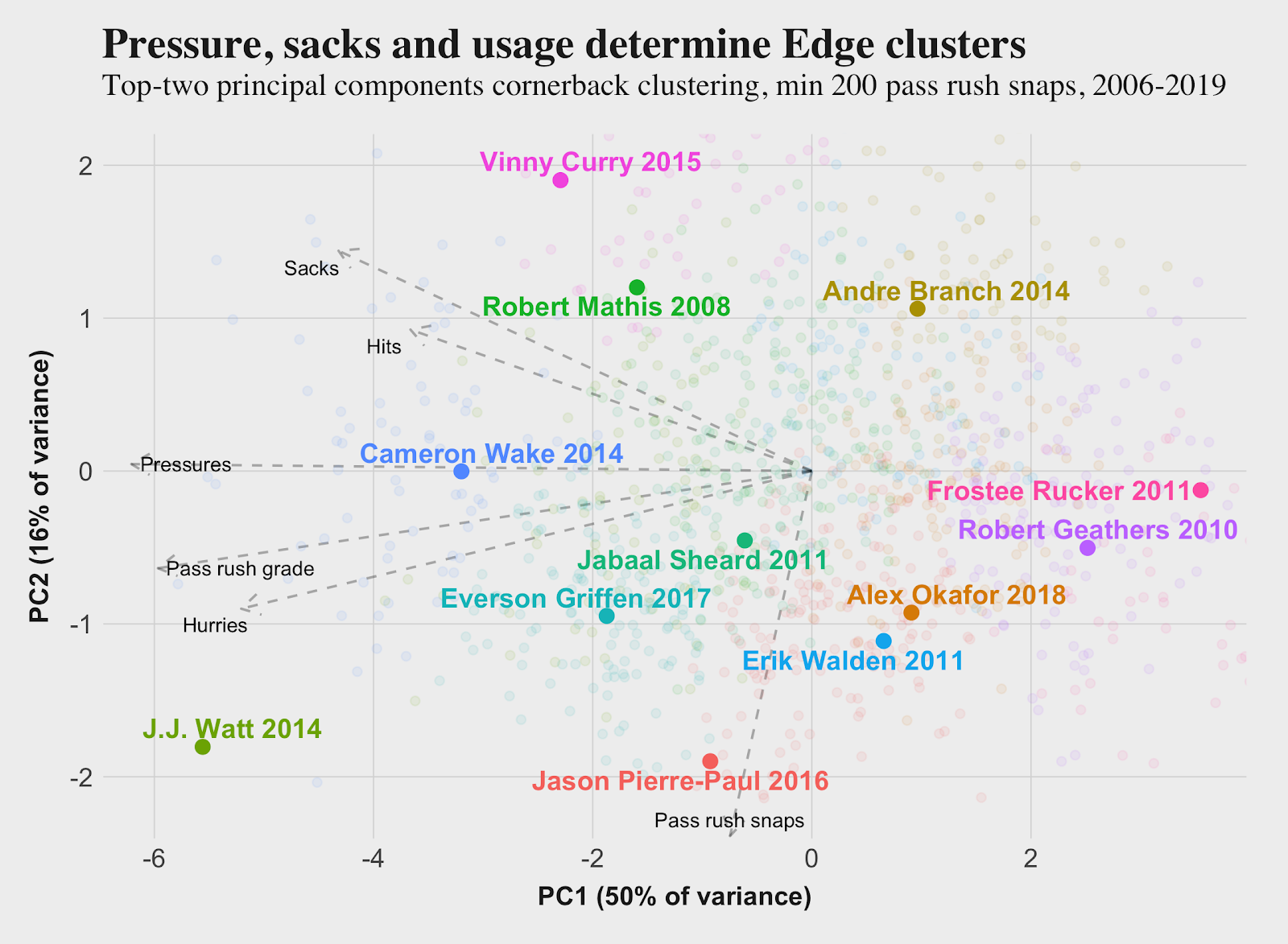
Every cluster is represented by a different color, and I highlighted one player from each who had the majority of his seasons placed into that cluster. For the remainder of this analysis, I will refer to the 12 clusters by the last name of the representative player, rather than cluster number.
The dashed arrows pointing to the left of the plot show the directionality of the different features. Edge seasons with a higher percentage of pass-rush snaps are lower, those who most often created more sacks, hits, hurries and pressures are generally to the left along with those who had better pass-rush grades. It’s within these 12 clusters that the individual numbers for each edge defender plus/minus are aggregated to determine the overall cluster plus/minuses.
A better view of how the players in each cluster differ can be seen using the spider charts below. First, we’ll look at the average numbers of the J.J. Watt cluster. Starting at the top, the features are in counter-clockwise rotation: pass-rush snaps per game (Snaps), sacks per snap, hits per snap, hurries per snap, pressures per snap and PFF pass-rush grade.
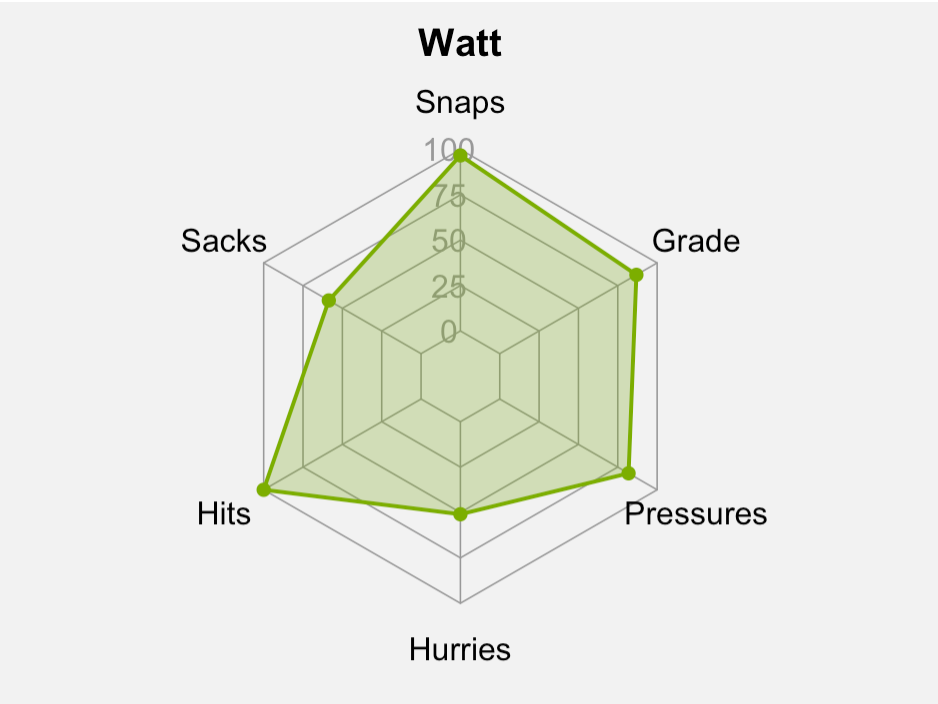
Watt is strong across the board, though slightly lower for sacks and hurries. Pressures are generally more predictive of future sacks than sacks are themselves, which means Watt’s lower total isn’t much of a negative. However, it must be noted that there is an element of double-counting here, as pressures encompass sacks, hits and hurries.
Here are all 12 clusters for comparison, from the expansive Watt cluster to one of the most limited, which is named after Frostee Rucker.

With the clusters sorted, we then calculate plus/minus splits per play for each cluster by adding together the total EPA for the opposing offenses when on the field, dividing that by total pass-rush snaps on the field and then subtracting the corresponding off-the-field figure from it. In this analysis, the edge defender plus/minus is framed in the view of the defense’s effect on the offense, i.e., negative EPA is good for the defensive player, and positive the opposite.
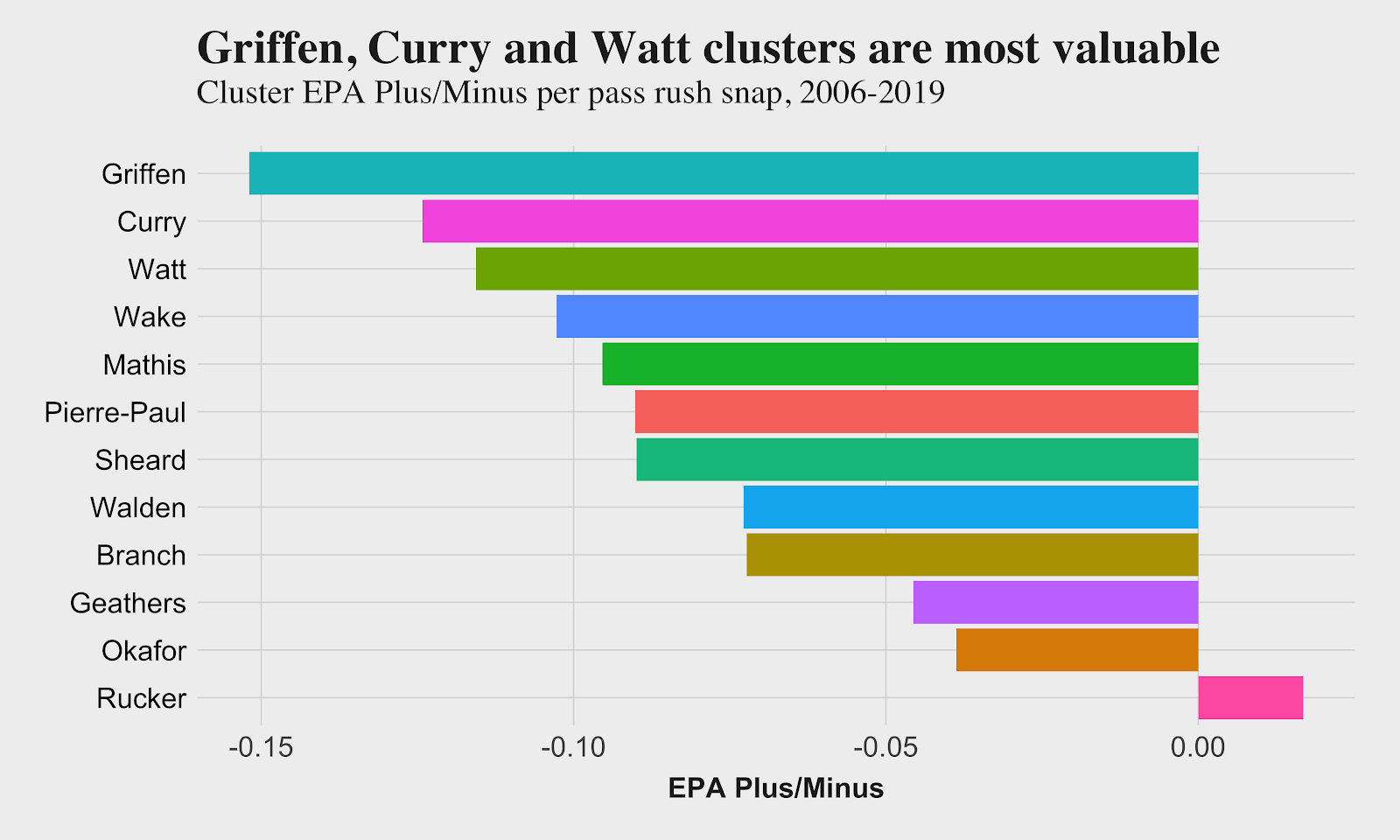
The big surprise in the results is that the Watt cluster is not the most valuable in this single clustering example. Luckily, we have a remedy for that by repeating the process, which I’ll detail below.
