
How many times have you heard something like, “In their last 20 games coming off a loss to a divisional opponent in primetime, Team A is 15-5 against the spread.”
In betting, this is called a trend. Trends use historical performance in various contexts to make predictions and betting recommendations for teams in similar spots.
At first, using this historical data to find forward-looking edges against the books seems like sound analytics. However, in practice, this sort of strategy commits a variety of analytics sins that eliminate any chance of predictiveness.
It’s easy to dismiss trend-based betting as inferior to model-based betting using tools like PFF’s Greenline, but let’s dig into the three most common types of analytical error — small sample size, data mining and priced-in signal — to explain exactly why bettors should cover their ears anytime they hear about a profitable NFL betting trend.
Click here for more PFF tools:
Rankings & Projections | WR/CB Matchup Chart | NFL & NCAA Betting Dashboards | NFL Player Props tool | NFL & NCAA Power Rankings
Small sample size
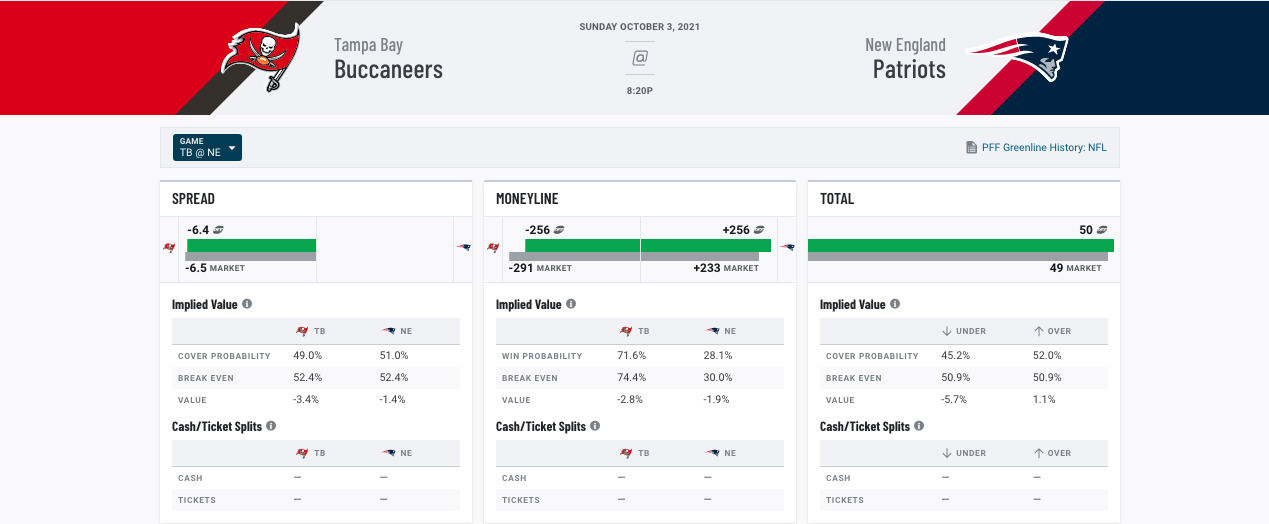
NFL spreads are 50/50 propositions. A bettor blindly betting sides will have a 50% win rate over the long term, which is not high enough to cover the cut charged by a sportsbook for taking a bet. However, much like flipping a coin, there’s actually a fairly high chance a bettor will have a success rate higher than 50% over a small enough sample of games due to random variance.
One way to separate skill from randomness is to use a binomial test, which calculates the likelihood a bettor will see an “X” covers over “Y” bet. Performance under this test is said to be “statistically significant” when the likelihood of achieving that performance by random luck is sufficiently small, usually less than 5%.
For instance, the binomial test tells us there is a 16% chance a bettor will cover 15 bets placed randomly at a rate of 60% or higher. While a 60% success rate is profitable, the 16% probability it was achieved through random variance is too high to consider it significant.
As the name suggests, betting trends that leverage small sample sizes to identify performances that are not statistically significant commit the small sample size error, as these are not predictive of future performance.
From 2015 to 2017, home underdogs of more than three points in Weeks 1 through 4 covered 60% of their 25 graded games (i.e., games where a push did not occur). While it may have looked as though backing long home underdogs early in the season was a profitable betting strategy in 2017, there wasn’t anything statistically significant about the trend. And from 2018 to 2020, these same teams covered only 40% of their graded games.
Long Home Dog |
||
| Home underdogs getting more than 3 points in Weeks 1-4 | ||
2015 to 2017 |
2018 to 2010 |
|
| Games | 25 | 33 |
| ATS% | 60.00% | 39.93% |
| Units won | 4 | -9 |
| Stat sig? | N | N |
A trend that leverages a small sample size like this is very unlikely to represent any actual edge. Instead, it’s likely to represent only random noise, which loses money over the long term as its performance regresses to the expected cover rate of 50%.
If small sample sizes are to be avoided, finding profitable betting strategies may seem as easy as identifying trends with sufficient sample size by guessing and checking various filtering criteria until a statistically significant betting strategy emerges. However, this trend identification strategy has problems of its own.
Data mining