One of the advantages of being a “data scientist” is that everyone assumes you know what you’re talking about. While that has its privileges, more important to the craft is the ability to leverage statistical programming packages like R and Python and apply them to almost any questions that can be answered through data.
Recently I started publishing analyses on the single-game DraftKings showdown slates that use the combination of current projections, historical game results and similarity algorithms to simulate an upcoming game by looking back at the most similar historical matchups. In this analysis I’m taking the same outline and applying it instead to the DFS slate by projecting the likelihood each individual QB, RB, WR, TE, and DST option will be the highest-scoring of the slate. In doing this, we can find the unlikely tournament plays who may not have been on your radar.
British statistician George E.P. Box once said, “All models are wrong, but some are useful,” and that’s the mindframe you should bring to this analysis. The numbers below are not “right” in the traditional sense of maximizing accuracy, which would only mimic the recommendations you’ll find throughout the DFS toutersphere. The numbers below are harnessing the unexpected connections and reactions between players that have actually happened over the past several years, and thereby points to under/overvalued players that won’t be identified through traditional projections and logical deduction.
METHODOLOGY
For each game on the DFS Conference Championship slate, I looked through thousands of NFL matchups from 2012-2018 and found the closest analogies according to the following parameters: Betting spread, over/under, average fantasy points scoring for the top-ranked positional players of both rosters (QB1, RB1, WR1, TE1).
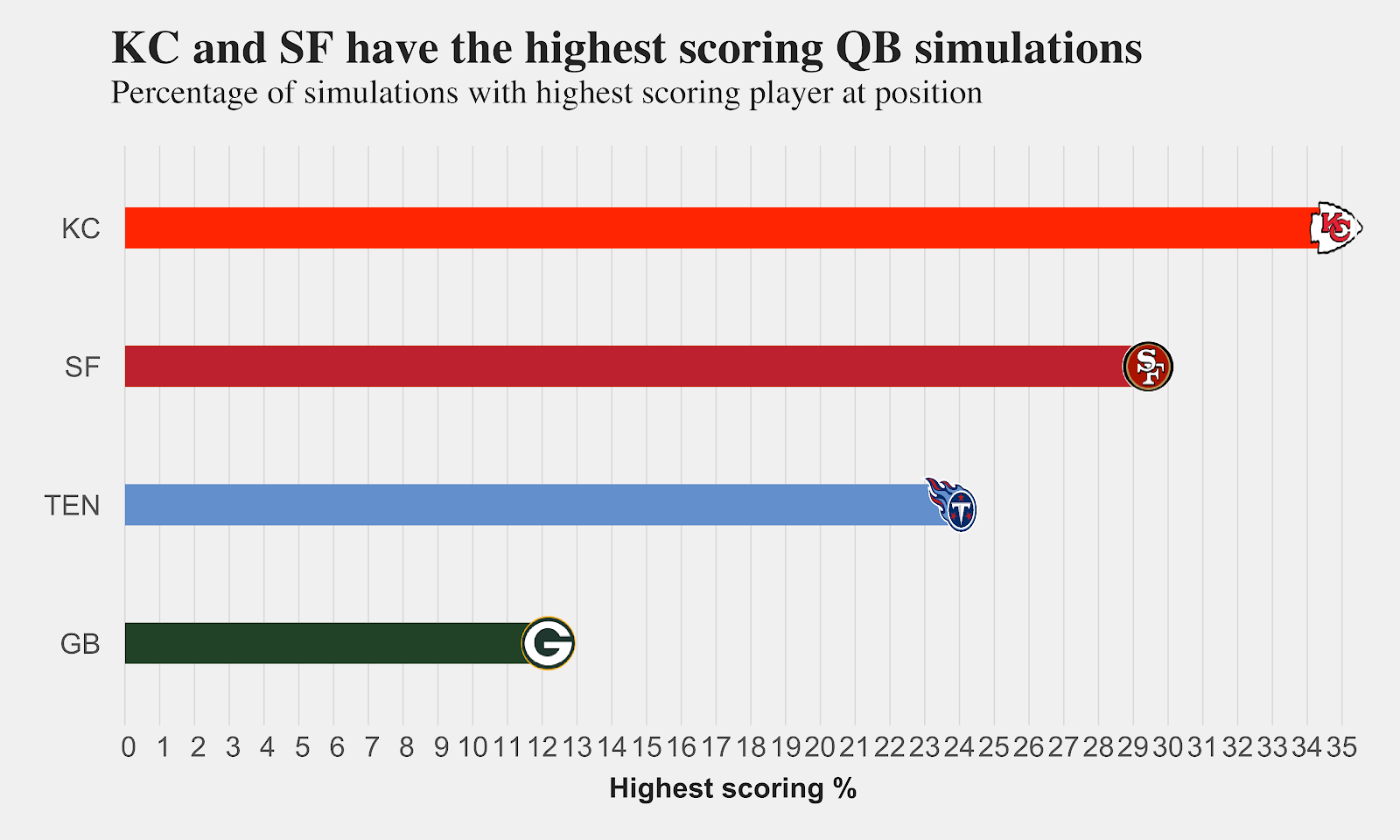
Once I find the 75 most similar matchups for each upcoming game, I then simulate the slate 10K times by randomly choosing one of the 75 matchups for each game and then find the highest-scoring QB, RB, WR, TE and DST on the entire slate.
Every match of historical and current games is not perfect, but by matching 75 different matchups to each game and simulating 10K times we can smooth out the bumps and get a strong picture of how a slate of similar games would have played out.
The last step is totaling up the number of times that a particular team shows up as the top option for the slate at each position and divide by the total simulations. That number is what I call “highest-scoring %” in the bar charts below labeled by team. Below the bar charts by team, I join the highest projected player on that team for the position and list his projected fantasy points and salaries for DraftKings and FanDuel.
QUARTERBACK